Explore our curated collection of the latest research in AI safety. Each entry represents a recent paper with a summary and link to the original source.
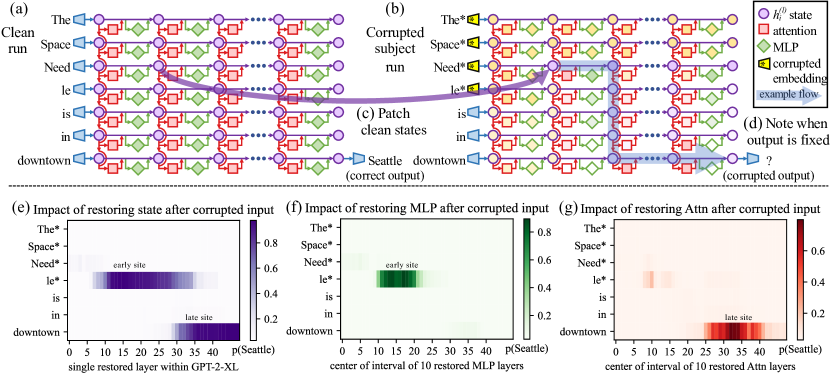
We analyze the storage and recall of factual associations in autoregressive transformer language models, finding evidence that these associations correspond to localized, directly-editable computations. We first develop a causal intervention for identifying neuron activations that are decisive in a model's factual predictions. This reveals a distinct set of steps in middle-layer feed-forward modules that mediate factual predictions while processing subject tokens. To test our hypothesis that these computations correspond to factual association recall, we modify feed-forward weights to update specific factual associations using Rank-One Model Editing (ROME). We find that ROME is effective on a standard zero-shot relation extraction (zsRE) model-editing task, comparable to existing methods. To perform a more sensitive evaluation, we also evaluate ROME on a new dataset of counterfactual assertions, on which it simultaneously maintains both specificity and generalization, whereas other methods sacrifice one or another. Our results confirm an important role for mid-layer feed-forward modules in storing factual associations and suggest that direct manipulation of computational mechanisms may be a feasible approach for model editing. The code, dataset, visualizations, and an interactive demo notebook are available at https://rome.baulab.info/
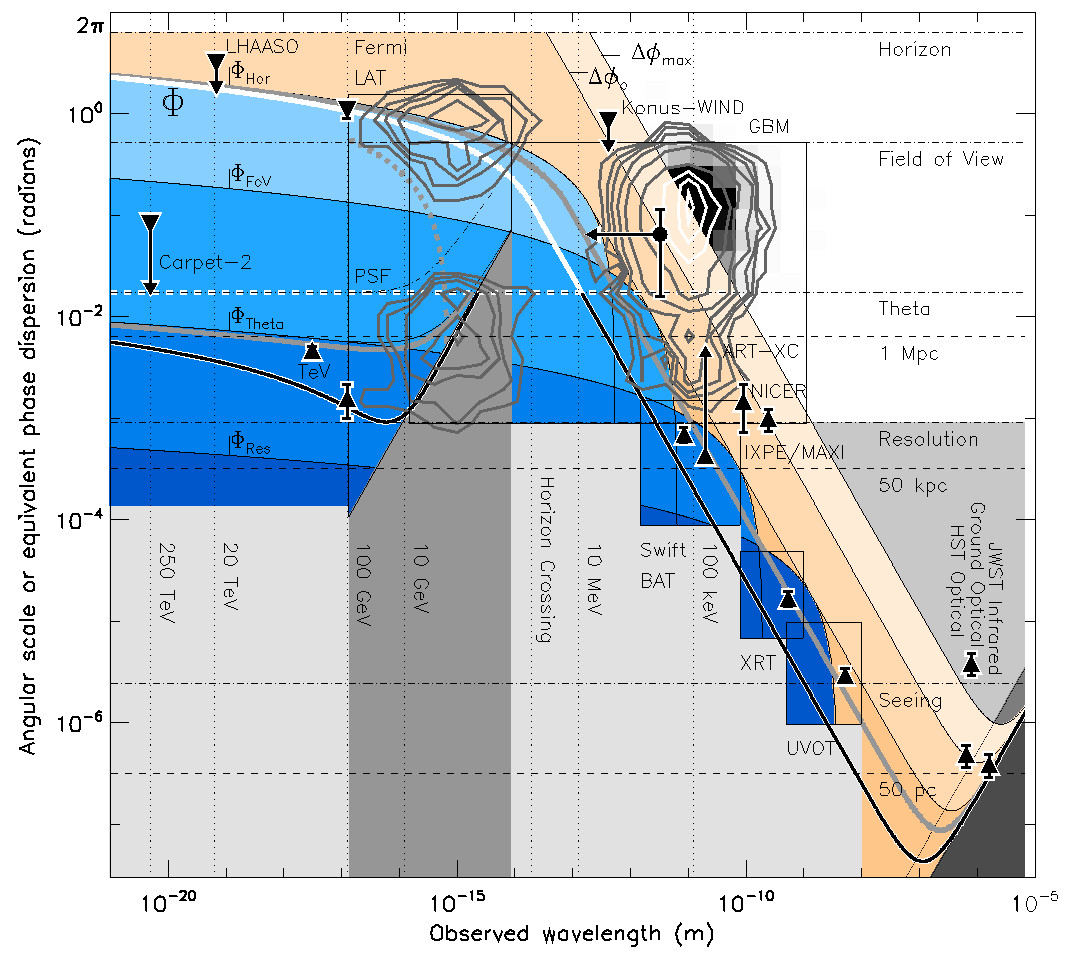
Gamma-ray burst GRB221009A was of unprecedented brightness in gamma-rays and X-rays, and through to the far ultraviolet, allowing for identification within a host galaxy at redshift z=0.151 by multiple space and ground-based optical/near-infrared telescopes and enabling a first association - via cosmic-ray air-shower events - with a photon of 251 TeV. That is in direct tension with a potentially observable phenomenon of quantum gravity (QG), where spacetime "foaminess" accumulates in wavefronts propagating cosmological distances, and at high-enough energy could render distant yet bright pointlike objects invisible, by effectively spreading their photons out over the whole sky. But this effect would not result in photon loss, so it remains distinct from any absorption by extragalactic background light. A simple multiwavelength average of foam-induced blurring is described, analogous to atmospheric seeing from the ground. When scaled within the fields of view for the Fermi and Swift instruments, it fits all z<5 GRB angular-resolution data of 10 MeV or any lesser peak energy and can still be consistent with the highest-energy localization of GRB221009A: a limiting bound of about 1 degree is in agreement with a holographic QG-favored formulation.
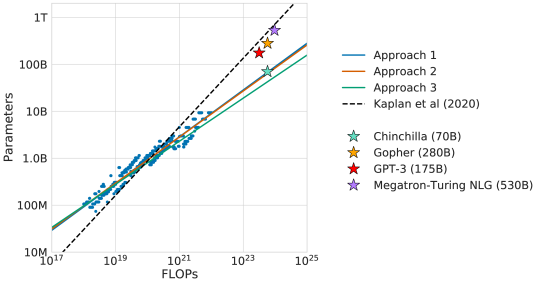
We investigate the optimal model size and number of tokens for training a transformer language model under a given compute budget. We find that current large language models are significantly undertrained, a consequence of the recent focus on scaling language models whilst keeping the amount of training data constant. By training over 400 language models ranging from 70 million to over 16 billion parameters on 5 to 500 billion tokens, we find that for compute-optimal training, the model size and the number of training tokens should be scaled equally: for every doubling of model size the number of training tokens should also be doubled. We test this hypothesis by training a predicted compute-optimal model, Chinchilla, that uses the same compute budget as Gopher but with 70B parameters and 4

This report proposes three arguments that safety cases could use in relation to scheming, and sketches how evidence could be gathered from empirical evaluations, and what assumptions would need to be met to provide strong assurance.

An argument that certain AI safety measures, rather than mitigating existential risk, may instead exacerbate it is presented, forcing a re-examination of core assumptions around AI safety and points to several avenues for further research.

The mystery of why models have so many seemingly redundant induction heads is explored, SAEs are used to motivate the hypothesis that some are long-prefix whereas others are short-prefix, and SAEs find a sparse, interpretable decomposition are shown.

A set of axioms are given that formally characterize a mechanistic interpretation as a description that approximately captures the semantics of the neural network under analysis in a compositional manner and are able to reverse engineer the algorithm learned by the model.

This work proposes a framework for organizing a safety case and discusses four categories of arguments to justify safety: total inability to cause a catastrophe, sufficiently strong control measures, trustworthiness despite capability to cause harm, and -- if AI systems become much more powerful -- deference to credible AI advisors.

A comprehensive meta-analysis of AI safety benchmarks is conducted, empirically analyzing their correlation with general capabilities across dozens of models and providing a survey of existing directions in AI safety, to provide a more rigorous framework for AI safety research.

It is suggested that an alternative and better approach to the problem may be to treat alignment as a social science problem, since the social sciences enjoy a rich toolkit of models for understanding and aligning motivation and behavior, much of which could be repurposed to problems involving AI models.

This paper proposes and evaluates three models for AISI involvement and offers a multi-track system solution in which the central role of AISIs guarantees coherence among the different tracks and consistency in their AI safety focus.

The results demonstrate that bilinear layers serve as an interpretable drop-in replacement for current activation functions and that weight-based interpretability is viable for understanding deep-learning models.

Sparse dictionary learning has been a rapidly growing technique in mechanistic interpretability to attack superposition and extract more human-understandable features from model activations. We ask a further question based on the extracted more monosemantic features: How do we recognize circuits connecting the enormous amount of dictionary features? We propose a circuit discovery framework alternative to activation patching. Our framework suffers less from out-of-distribution and proves to be more efficient in terms of asymptotic complexity. The basic unit in our framework is dictionary features decomposed from all modules writing to the residual stream, including embedding, attention output and MLP output. Starting from any logit, dictionary feature or attention score, we manage to trace down to lower-level dictionary features of all tokens and compute their contribution to these more interpretable and local model behaviors. We dig in a small transformer trained on a synthetic task named Othello and find a number of human-understandable fine-grained circuits inside of it.

Fueled by the popularity of the transformer architecture in deep learning, several works have investigated what formal languages a transformer can learn. Nonetheless, existing results remain hard to compare and a fine-grained understanding of the trainability of transformers on regular languages is still lacking. We investigate transformers trained on regular languages from a mechanistic interpretability perspective. Using an extension of the

What evidence patching experiments provide about circuits, and on the choice of metric and associated pitfalls, are focused on.

End-to-end (e2e) sparse dictionary learning is proposed, a method for training SAEs that ensures the features learned are functionally important by minimizing the KL divergence between the output distributions of the original model and the model with SAE activations inserted.

Sparse Autoencoders (SAEs) have emerged as a powerful unsupervised method for extracting sparse representations from language models, yet scalable training remains a significant challenge. We introduce a suite of 256 SAEs, trained on each layer and sublayer of the Llama-3.1-8B-Base model, with 32K and 128K features. Modifications to a state-of-the-art SAE variant, Top-K SAEs, are evaluated across multiple dimensions. In particular, we assess the generalizability of SAEs trained on base models to longer contexts and fine-tuned models. Additionally, we analyze the geometry of learned SAE latents, confirming that \emph{feature splitting} enables the discovery of new features. The Llama Scope SAE checkpoints are publicly available at~\url{https://huggingface.co/fnlp/Llama-Scope}, alongside our scalable training, interpretation, and visualization tools at \url{https://github.com/OpenMOSS/Language-Model-SAEs}. These contributions aim to advance the open-source Sparse Autoencoder ecosystem and support mechanistic interpretability research by reducing the need for redundant SAE training.

This review explores mechanistic interpretability: reverse engineering the computational mechanisms and representations learned by neural networks into human-understandable algorithms and concepts to provide a granular, causal understanding of AI systems' inner workings.

This paper explores the mechanistic interpretability of reinforcement learning (RL) agents through an analysis of a neural network trained on procedural maze environments. By dissecting the network's inner workings, we identified fundamental features like maze walls and pathways, forming the basis of the model's decision-making process. A significant observation was the goal misgeneralization, where the RL agent developed biases towards certain navigation strategies, such as consistently moving towards the top right corner, even in the absence of explicit goals. Using techniques like saliency mapping and feature mapping, we visualized these biases. We furthered this exploration with the development of novel tools for interactively exploring layer activations.

A novel hallucination mitigation method is proposed through targeted restoration of the LM's internal fact recall pipeline, demonstrating superior performance compared to baselines.

Methods for knowledge editing and unlearning in large language models seek to edit or remove undesirable knowledge or capabilities without compromising general language modeling performance. This work investigates how mechanistic interpretability -- which, in part, aims to identify model components (circuits) associated to specific interpretable mechanisms that make up a model capability -- can improve the precision and effectiveness of editing and unlearning. We find a stark difference in unlearning and edit robustness when training components localized by different methods. We highlight an important distinction between methods that localize components based primarily on preserving outputs, and those finding high level mechanisms with predictable intermediate states. In particular, localizing edits/unlearning to components associated with the lookup-table mechanism for factual recall 1) leads to more robust edits/unlearning across different input/output formats, and 2) resists attempts to relearn the unwanted information, while also reducing unintended side effects compared to baselines, on both a sports facts dataset and the CounterFact dataset across multiple models. We also find that certain localized edits disrupt the latent knowledge in the model more than any other baselines, making unlearning more robust to various attacks.

We propose Scalable Mechanistic Neural Network (S-MNN), an enhanced neural network framework designed for scientific machine learning applications involving long temporal sequences. By reformulating the original Mechanistic Neural Network (MNN) (Pervez et al., 2024), we reduce the computational time and space complexities from cubic and quadratic with respect to the sequence length, respectively, to linear. This significant improvement enables efficient modeling of long-term dynamics without sacrificing accuracy or interpretability. Extensive experiments demonstrate that S-MNN matches the original MNN in precision while substantially reducing computational resources. Consequently, S-MNN can drop-in replace the original MNN in applications, providing a practical and efficient tool for integrating mechanistic bottlenecks into neural network models of complex dynamical systems.

This work introduces a novel method for using transcoders to perform weights-based circuit analysis through MLP sublayers, and suggests that transcoders can prove effective in decomposing model computations involving MLPs into interpretable circuits.

This research analyzes the look-ahead planning mechanisms of LLMs, facilitating future research on LLMs performing planning tasks and finding that the output of MHSA in the middle layers at the last token can directly decode the decision to some extent.

Mechanistic Interpretability aims to reverse engineer the algorithms implemented by neural networks by studying their weights and activations. An obstacle to reverse engineering neural networks is that many of the parameters inside a network are not involved in the computation being implemented by the network. These degenerate parameters may obfuscate internal structure. Singular learning theory teaches us that neural network parameterizations are biased towards being more degenerate, and parameterizations with more degeneracy are likely to generalize further. We identify 3 ways that network parameters can be degenerate: linear dependence between activations in a layer; linear dependence between gradients passed back to a layer; ReLUs which fire on the same subset of datapoints. We also present a heuristic argument that modular networks are likely to be more degenerate, and we develop a metric for identifying modules in a network that is based on this argument. We propose that if we can represent a neural network in a way that is invariant to reparameterizations that exploit the degeneracies, then this representation is likely to be more interpretable, and we provide some evidence that such a representation is likely to have sparser interactions. We introduce the Interaction Basis, a tractable technique to obtain a representation that is invariant to degeneracies from linear dependence of activations or Jacobians.