Summary
This paper presents a novel approach to interpreting attention mechanisms in transformer models using Sparse Autoencoders (SAEs). The authors demonstrate that SAEs can effectively decompose attention layer outputs into interpretable features, providing new insights into how attention layers process information.
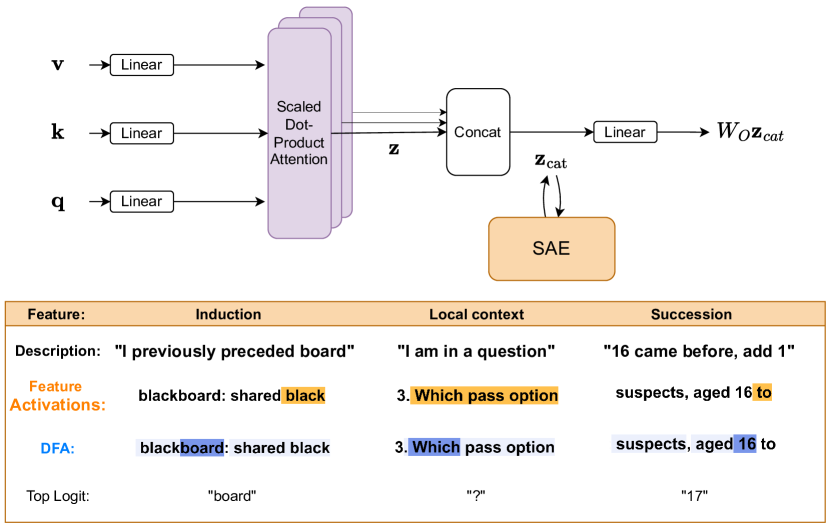
The key contributions include:
-
Novel Application of SAEs: The authors show that SAEs can successfully decompose attention layer outputs into sparse, interpretable features across multiple model families up to 2B parameters. They train SAEs on the concatenated outputs of attention heads before the final linear projection.
-
Feature Families: Through qualitative analysis, they identify three main families of attention features:
- Long-range context features
- Short-range context features
- Induction features
- Polysemanticity Analysis: The research reveals that approximately 90% of attention heads in GPT-2 Small are polysemantic (performing multiple unrelated tasks), challenging previous approaches to interpreting individual attention heads.
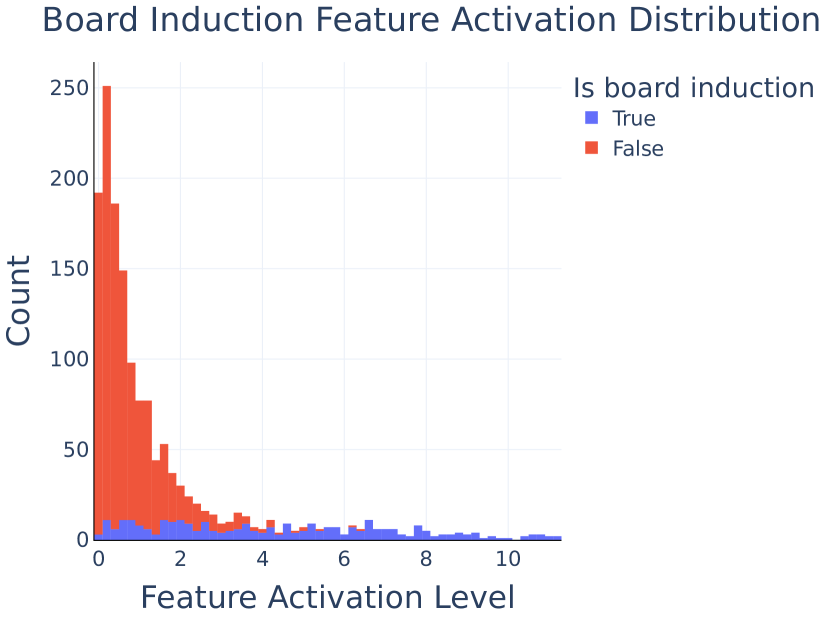
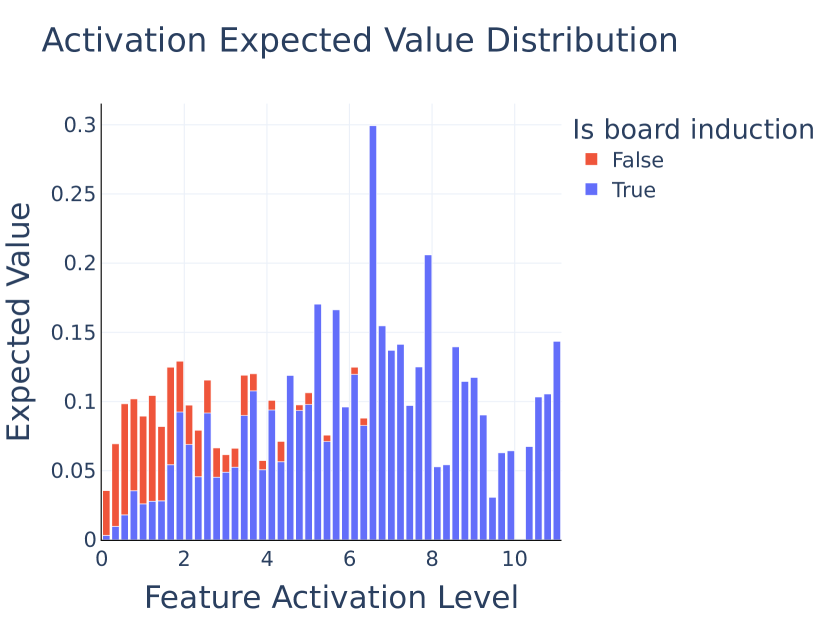
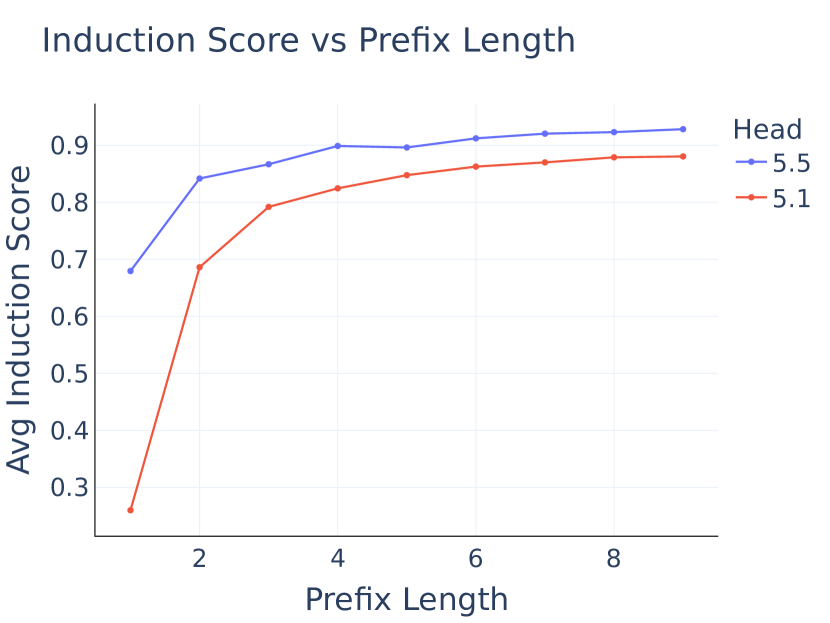
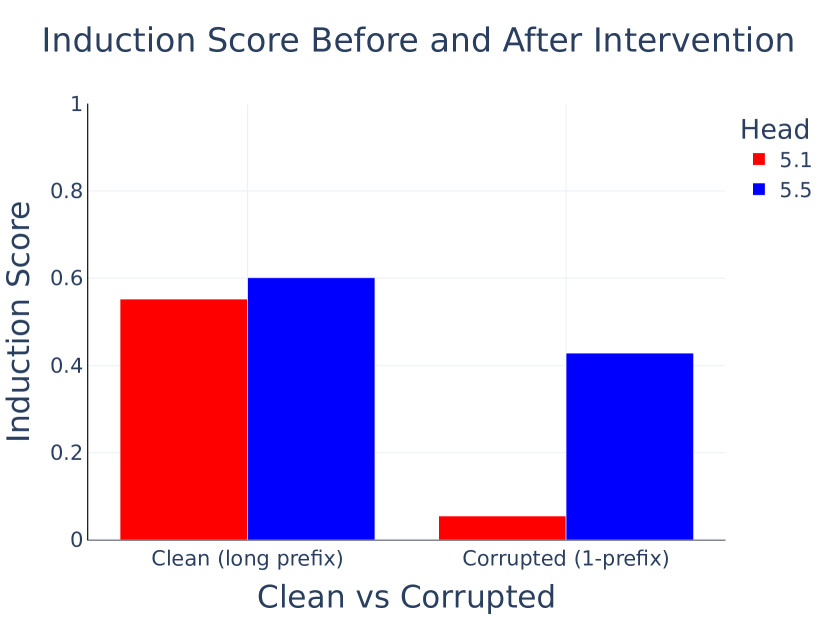
- Long-Prefix Induction: The authors make progress on understanding why models have multiple seemingly redundant induction heads, showing that some specialize in “long-prefix” vs “short-prefix” induction patterns.
A particularly significant contribution is their analysis of the Indirect Object Identification (IOI) circuit, where they discover that the “positional signal” is determined by whether duplicate names appear before or after “and” tokens. This provides concrete evidence of how the model processes relative positioning information.
Figure 14
The methodology includes several novel techniques:
- Weight-based head attribution
- Direct feature attribution (DFA)
- Recursive Direct Feature Attribution (RDFA)
Figure 16
The authors validate their findings through multiple independent lines of evidence and provide extensive evaluations across different model scales. They also release their trained SAEs and visualization tools to support further research.
The paper’s limitations are thoughtfully addressed, including the focus on attention outputs rather than the full transformer architecture and the reliance on qualitative investigations and human judgment in some analyses.
This work represents a significant advance in mechanistic interpretability, providing both theoretical insights and practical tools for understanding how attention mechanisms process information in transformer models.
The most important figures are:
- Figure 1: Overview of the SAE approach
- Figure 2: Specificity analysis of induction features
- Figure 4: Evidence for long-prefix specialization
- Figures 14 & 16: IOI circuit analysis results
Figure 1 would make the best thumbnail as it clearly illustrates the paper’s core concept of using SAEs to interpret attention layer outputs.