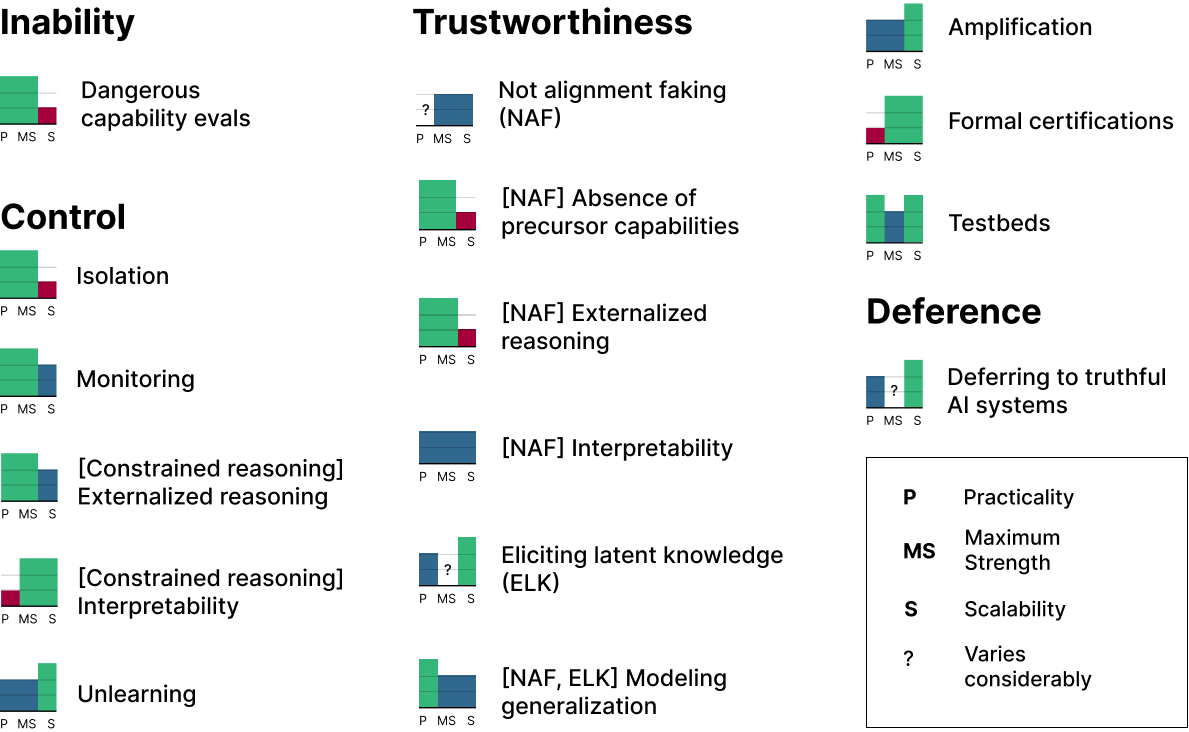Safety Cases: How to Justify the Safety of Advanced AI Systems
Authors
Joshua Clymer, Nick Gabrieli, David Krueger, Thomas Larsen
Abstract
As AI systems become more advanced, companies and regulators will make difficult decisions about whether it is safe to train and deploy them. To prepare for these decisions, we investigate how developers could make a 'safety case,' which is a structured rationale that AI systems are unlikely to cause a catastrophe. We propose a framework for organizing a safety case and discuss four categories of arguments to justify safety: total inability to cause a catastrophe, sufficiently strong control measures, trustworthiness despite capability to cause harm, and -- if AI systems become much more powerful -- deference to credible AI advisors. We evaluate concrete examples of arguments in each category and outline how arguments could be combined to justify that AI systems are safe to deploy.
This comprehensive paper presents a framework for developing and evaluating safety cases for advanced AI systems. The authors propose a structured approach to justify that AI systems are unlikely to cause catastrophic outcomes during deployment.
Key Contributions:
Framework Structure
The paper outlines a six-step framework for constructing AI safety cases:
Define the AI macrosystem and deployment decision
Specify unacceptable outcomes
Justify deployment assumptions
Decompose the macrosystem into subsystems
Assess subsystem risk
Assess macrosystem risk
Safety Argument Categories
The authors identify four main categories of safety arguments (
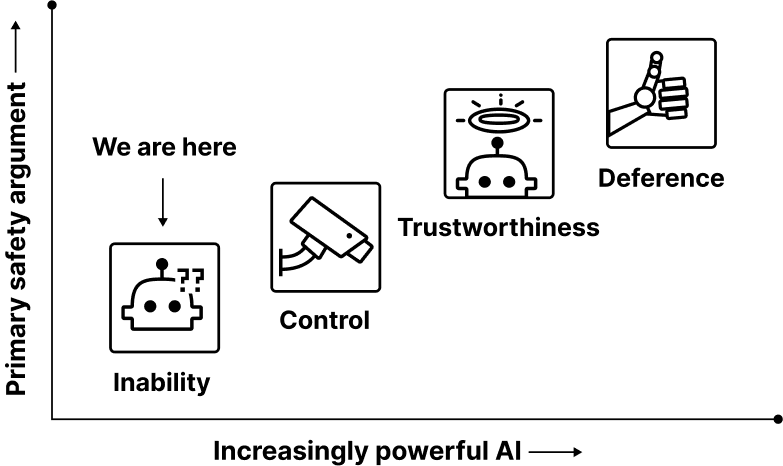
Figure 2: As AI systems become more powerful, developers will likely increasingly rely on arguments toward the right in the plot above.
Figure 2: As AI systems become more powerful, developers will likely increasingly rely on arguments toward the right in the plot above.
Figure 2):
Inability: Demonstrating AI systems cannot cause catastrophes
Control: Showing control measures prevent catastrophic outcomes
Trustworthiness: Proving AI systems behave reliably despite capabilities
Deference: Relying on credible AI advisors’ safety assessments
Building Block Arguments
The paper presents a detailed analysis of specific arguments within each category (
Figure 3: building block arguments for making safety cases. See section 5 for detailed descriptions of each building block argument and justifications for their labels. The arguments that rank highest on practicality, strength, and scalability are monitoring, externalized reasoning, and testbeds.
Figure 3: building block arguments for making safety cases. See section 5 for detailed descriptions of each building block argument and justifications for their labels. The arguments that rank highest on practicality, strength, and scalability are monitoring, externalized reasoning, and testbeds.
Figure 3), rating them on:
Practicality: How soon they could be implemented
Maximum strength: Potential confidence in safety
Scalability: Applicability to more advanced AI systems
Holistic Safety Case Construction
The authors demonstrate how to combine these arguments into a complete safety case using Goal Structuring Notation (GSN) (
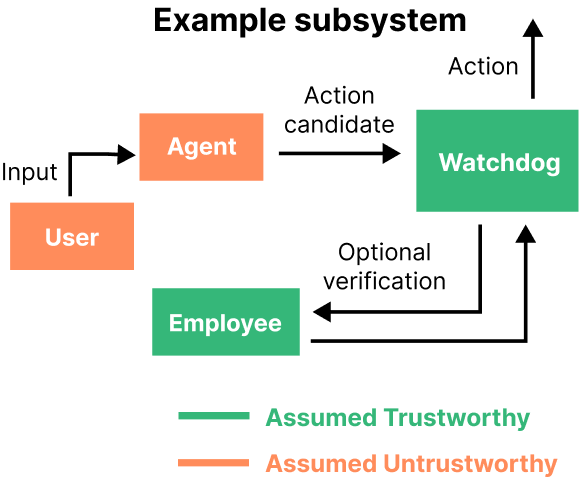
Figure 8: Caption: The diagram above illustrates an example monitoring scheme where a watchdog model (right) monitors the agent model (left). In this setup, a control argument could be constructed by conservatively assuming that the agent and its users are pursuing their best strategy for causing a catastrophe (untrustworthy). The watchdog is assumed to be reliable, which must be justified with a trustworthiness argument.
Figure 8: Caption: The diagram above illustrates an example monitoring scheme where a watchdog model (right) monitors the agent model (left). In this setup, a control argument could be constructed by conservatively assuming that the agent and its users are pursuing their best strategy for causing a catastrophe (untrustworthy). The watchdog is assumed to be reliable, which must be justified with a trustworthiness argument.
Figure 8,
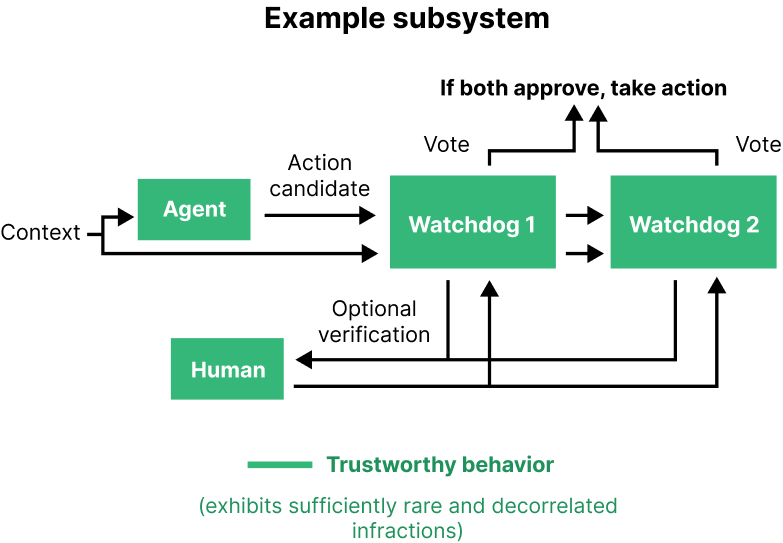
Figure 9: the diagram above depicts a potential setup where three different models would need to behave badly to cause a catastrophe.
Figure 9: the diagram above depicts a potential setup where three different models would need to behave badly to cause a catastrophe.
Figure 9).
Risk Assessment
The paper discusses approaches to evaluating both individual subsystem risks and interactions between subsystems (
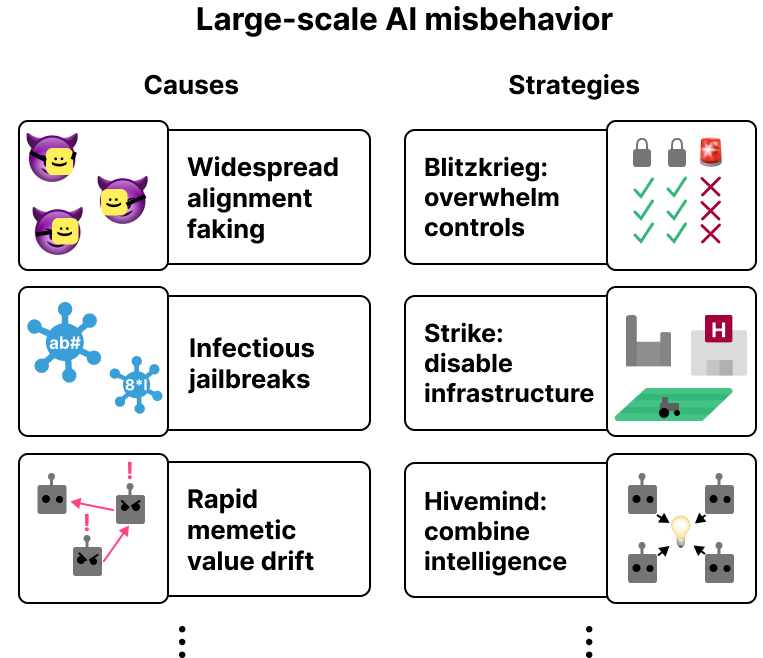
Figure 16: The figure lists examples of strategies that AI systems could pursue collectively at a large scale to cause a catastrophe (right) as well as reasons AI systems might pursue them.
Figure 16: The figure lists examples of strategies that AI systems could pursue collectively at a large scale to cause a catastrophe (right) as well as reasons AI systems might pursue them.
Figure 16). It emphasizes the importance of considering collective behavior and potential coordination between AI systems.
Bootstrapping Safety Arguments
The authors present a novel approach to scaling safety arguments to more powerful AI systems through gradual amplification (
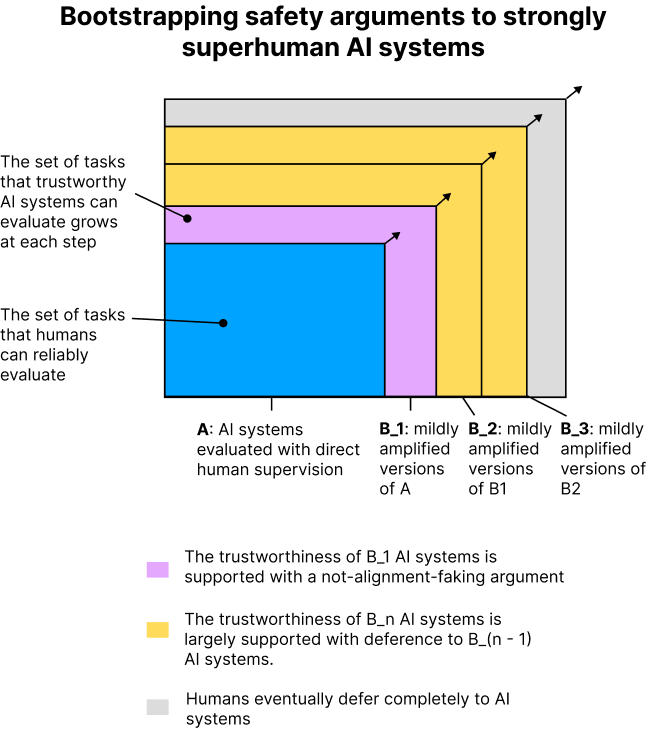
Figure 10: The diagram above shows how not-alignment-faking arguments could be bootstrapped up to strongly superhuman AI systems. This particular strategy is called iterated amplification (Christiano et al.,, 2018). AI systems can be ‘amplified’ by creating additional copies of them or speeding them up (see section A.3.6).
Figure 10: The diagram above shows how not-alignment-faking arguments could be bootstrapped up to strongly superhuman AI systems. This particular strategy is called iterated amplification (Christiano et al.,, 2018). AI systems can be ‘amplified’ by creating additional copies of them or speeding them up (see section A.3.6).
Figure 10).
Most Important Figures:
Figure 2 provides the clearest overview of how safety arguments evolve with AI capability
Figure 3 offers a comprehensive visualization of different safety argument types and their characteristics
Figure 16 illustrates important considerations for large-scale AI misbehavior
The paper makes a significant contribution by providing a structured framework for evaluating AI safety, while acknowledging that many of the proposed arguments require further research and development. It serves as both a practical guide for current AI safety evaluation and a roadmap for future research directions.
Figure 2 would make the best thumbnail as it clearly illustrates the progression of safety argument types as AI systems become more powerful, capturing a key insight of the paper in a single, accessible image.