Summary
This paper presents a comprehensive analysis of non-factual hallucinations in large language models (LMs), identifying two distinct mechanisms through which these errors occur and proposing a novel method for mitigating them. Key Contributions:
- Identification of Two Hallucination Types:
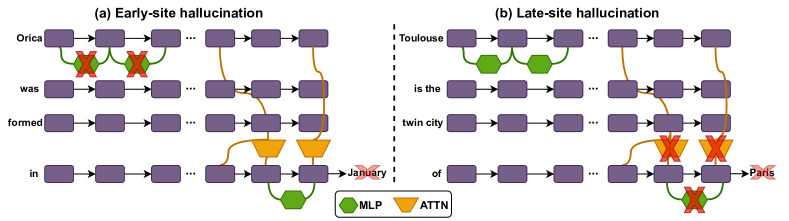
Figure 1 - Knowledge Enrichment Hallucinations: Occur when lower-layer MLPs fail to retrieve sufficient subject attribute knowledge - Answer Extraction Hallucinations: Happen when upper-layer attention heads fail to select the correct object attribute
- Empirical Analysis: The researchers analyzed three major LMs (Llama-2, Pythia, GPT-J) using the ParaRel dataset of cloze-style factual queries.
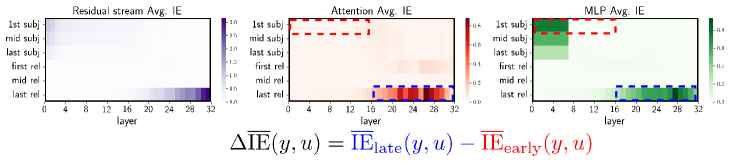
Figure 2 shows the distribution of true answer rankings across models, revealing distinct patterns for factual vs hallucinating responses.
- Mechanistic Investigation:
[See Figure 3 in the original paper]
Using logit lens and causal mediation analysis, they traced how information flows through the models, showing: - Early/middle layer MLPs are crucial for knowledge retrieval - Upper layer attention heads are responsible for answer selection - Different failure modes in these components lead to different types of hallucinations
-
External Manifestations: The two hallucination types show distinct characteristics: - Answer extraction hallucinations have stronger subject-object associations - Knowledge enrichment hallucinations show higher uncertainty and lower robustness - These patterns are consistent across all tested models
-
Mitigation Method: The authors developed a Mechanistic Hallucination Mitigation (MHM) method that: - Targets both knowledge enrichment and answer extraction mechanisms - Achieves superior performance compared to baseline methods - Maintains model utility while reducing hallucinations Results: As shown in Table 3, the MHM method outperformed existing approaches on both Natural Questions and TruthfulQA datasets, with: - Higher effectiveness on paraphrased questions - Better preservation of model performance on correctly-answered questions - Consistent improvements across all tested models The research provides valuable insights into how and why LMs hallucinate, offering both theoretical understanding and practical solutions for improving model factuality. The methodology combines rigorous analysis of internal model mechanisms with empirical validation of external behaviors. Most Important Figures: Figure 1 is crucial as it illustrates the two distinct hallucination mechanisms, making it an ideal thumbnail. Figure 3 provides detailed empirical evidence supporting the theoretical framework, while Table 3 demonstrates the practical impact of the proposed solution.